본 문서는 다음과 같은 사이트를 참고하였습니다.
Gensim
ratsgo - 토픽모델링
텍스트마이닝과 토픽모델링
데이터마이닝의 한 분야인 텍스트마이닝은 텍스트문서, 이메일, HTML문서와 같이 비구조화(Unstructured), 혹은 반구조화(Semi-Structured) 된 텍스트문서에서 새로운 정보를 추출하는 정보기술로, 토픽모델링은 텍스트 마이닝에서 사용하는 연구방법론이라고 합니다. 가장 대표적인 토픽모델링 기법인 Blei etal.(2003)의 LDA(Latent Dirichlet Allocation)은 다수의 문서에서 잠재적으로 의미 있는 토픽을 발견하는 절차적 확률 분포 모델이다. LDA는 단어들의 집합이 어떤 토픽들로 묶인다고 가정하고, 이 단어들이 각각의 토픽에 구성될 확률을 계산하여 결과 값을 토픽에 해당할 가능성이 높은 단어들의 집합으로 추출하는 방식이다.
지식경영연구 제 16권 4호 소셜미디어 토픽모델링을 통한 스마트폰 마케팅 전략 수립 지원 중
Gensim이란?
주어진 기사에 가장 유사한 기사를 생성하는 기능을 구현하고 싶었던 개발자들이 만들어낸 라이브러리 입니다.(gensim = “generate similar”). “Latent Semantic Methods”을 개발하고자 시작했던 개발자가 딱히 쓸만한 라이브러리가 없어서 자기가 만들었다고 합니다.(ph.D 주제를 단어의 분산표현이라합니다)
algorithmic scalability of distributional semantics the topic of my PhD thesis.
Gensim은 OSI 승인 GNU LGPLv2.1 라이센스에 따라 라이센스가 부여됩니다. 이는 개인적으로나 상업적으로나 자유롭게 사용할 수 있다는 것을 의미하지만, 다른 사람들에게 배포하는 Gensim을 수정하면 이러한 수정의 소스 코드를 공개해야합니다.
LDA에 대해서 이해해보자
위에서 토픽 모델링은 다수의 문서에서 잠재적으로 의미있는 토픽을 발견하고 절차적 확률 분포모델을 구성한다고 하였습니다. 너무 어려운 이야기가 많이 나오지만 그렇다면 핵심만 기억해 봅시다. 토픽모델링은 많은 문서들 내에서 등장하는 공통된 의미를 찾아주는 방법론입니다. 이때의 공통된 의미는 이면에 존재하는 정보이기 때문에 Latent 라는 의미가 붙게 되었습니다
토픽모델링의 특징은 문서집합의 내부 정보를 통해 모델링이 완성이 되며, 주제는 숨겨져 있는 latent한 요소가 됩니다. 또한 EM알고리즘을 기반으로 확률적 모델링이 진행되기 때문에 주제에 대한 clustering 이라고 할 수 있스빈다.
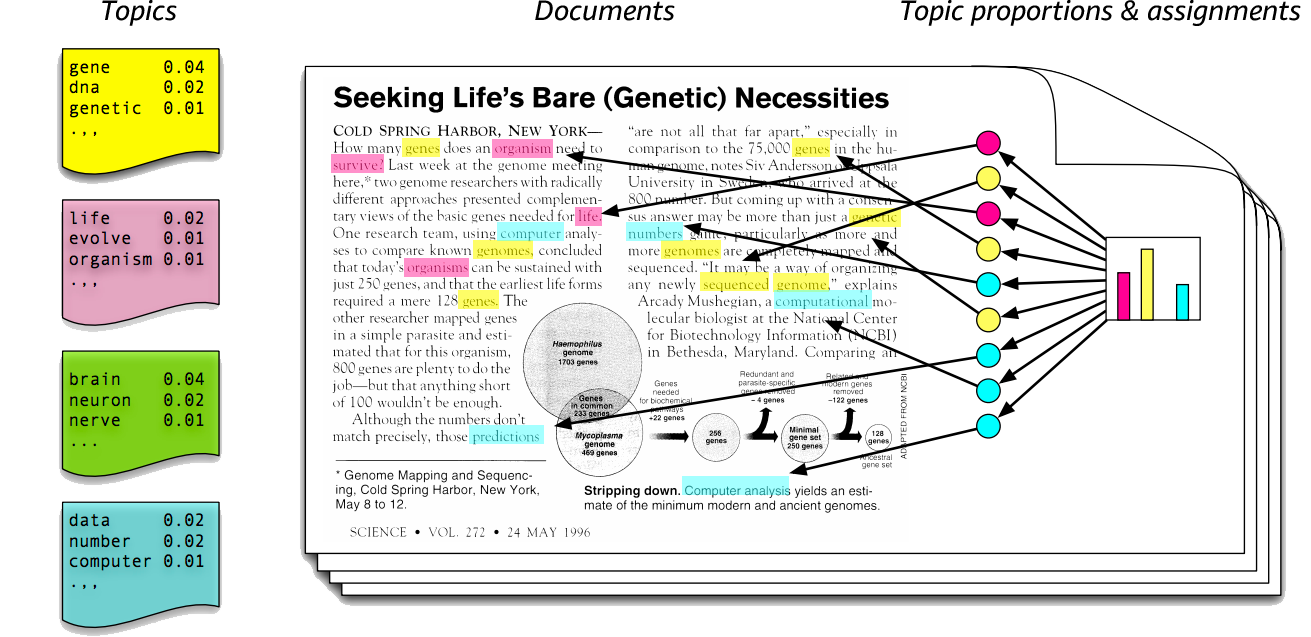
LDA를 통해서 그러면 무엇을 알 수 있을까요? LDA를 이해하기 위해서는 3가지 관점에서 보시면 좋습니다. 첫번째는 공통된 의미를 뜻하는 잠재된 주제, 그리고 데이터 포인트를 나타내주는 문서들, 그리고 문서들 속에서 문서를 구성해주는 단어들, 이들을 각각 Topic, Documents, Terms 라고 말하도록 하겠습니다. LDA모형에서는 단어로 부터 문서가 생성되는 과정을 확률 모형으로 모델링한 것입니다. 마치 글을 쓸 때 글감을 정하는 것과 비슷합니다.
글감은 위에서 말한 Topic에 실제 사용되는 단어들은 Terms 에 그렇게 나온 문서들을 Documents라고 생각하시면 됩니다.
LDA로 무엇을 할껀가요?? - Auto tagging
저희 코어닷 투데이는, 다양한 문서 데이터에 대한 색인어를 찾아내는 작업을 할 것입니다. 목적은 각각의 문서를 대표하는 주제어를, LDA의 Topic 모형으로 부터 추출해 내어서, 그 주제를 대표하는 단어와, 문서안에 문서를 구성하는 단어의 공통점을 주제어로 태깅을 하게 되는 것이죠. 이러한 방법론의 장점으로 예상이 되는 것은 각각 문서에 대해서 문서의 고유한 정보가 반영됨과 동시에, 모든 관보 문서를 학습해서 나오는 문서 전체의 토픽의 의미에 대해서도 알 수 있는 점입니다.
앞으로의 포스트를 보면서 어떻게 발전할지 한번 지켜봐 주세요!