본 문서는 다음과 같은 사이트를 참고하였습니다.
- https://radimrehurek.com/gensim/tut1.html
- https://statkclee.github.io/text/
- https://ratsgo.github.io/from%20frequency%20to%20semantics/2017/03/10/frequency/
NLP의 활용 분야
앞에서 기본적인 NLP분야들을 살펴 보았습니다. 특히 자연어 이해, 자연어 생성, 기계번역, 질의응답 시스템, 음성인식, 음성합성, 음성이해, 정보분류, 문서 분류, 텍스트 마이닝등 분야들이 존재한다. 이중에서 필자가 관심있는 것은 정보 분류, 문서 분류, 텍스트 마이닝 등이였습니다. 이번 시간에는 문서 분류와 토픽 모델링을 위해서 기본적으로 진행할 요소들을 공부해 보려고 합니다.
본격적인 자연어 처리를 위해서 데이터를 가져오자
사용한 라이브러리는 다음과 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
# 데이터베이스로드
from pymongo import MongoClient
# 데이터 프레임 관리
import pandas as pd
# 선형 대수
import numpy as np
# 정규 표현식
import re
# 자연어 처리 모듈
import coredottext.nlp as nlp
# api 데이터 처리를 위함
import requests
import json
데이터 로드 : Mongodb
본 프로젝트는 데이터는 엘라스틱 서치를 기반으로 api 형태로 데이터를 받아오게 되었습니다. 하지만 보안상 이유로 dummy로 프로젝트 문서를 구성하였습니다. 위해서 mongodb형태의 예제를 준비했습니다. 본 데이터는 정부에서 국민들에게 헌법,법률,명령,규칙등 행정,입법,사법부의 결정들을 국민들에게 전달하여, 정부의 변화를 국민들에게 전달하기 위함에 있습니다.
본 튜토리얼은 국토교통부 의 200개의 관보 데이터를 기반으로 제작하게 되었습니다. 데이터는 여기 에서 다운로드 받으실 수 있습니다.
데이터를 다운로드 받으셨다면 한번 mongodb를 활용하여 넣어봅시다.
1
2
3
4
5
# 데이터를 로드해 봅시다
client = MongoClient()
db = client.LDAtutorial
data = db.example.find()
datalist = list(data)
데이터를 로드하고 list형태로 변환한 뒤, value부분만 받아옵시다.
1
2
3
docs = []
for i in datalist:
docs.append(i['data'])
이후 첫번째 데이터를 조회해보면, 파이썬의 dictionary형태로 모여있는걸 알 수 있습니다.
1
docs[1]
{'content': ' 도로법 시행령 을 개정하는 데에 있어, 그 개정이유와 주요내용을 국민에게 미리 알려 이에 대한 의견을 듣기 위하여 행정절차법 제41조에 따라 다음과 같이 공고합니다. 2017년 3월 16일 국토교통부장관 도로법 시행령 일부개정령(안) 입법예고 1. 개정이유 도로법 제68조 도로점용료 감면조항에「영유아보육법」제2조제3호에 따른 어린이집 또는「유아교 육법」제2조제2호에 따른 유치원(민간어린이집과 민간유치원)에 출입하기 위하여 통행로로 사용하는경우가 신설되었기에 이에 대한 하위법령을 마련하고자 함2. 주요내용 가. 도로점용료 감면 대상 추가(안 제73조제3항제1호가목) ㅇ 도로법 제68조(점용료 징수의 제한) 제9호 “「영유아보육법」제2조제3호에 따른 어린이집 또는「유아교육법」제2조제2호에 따른 유치원에 출입하기 위하여 통행로로 사용하는 경우” 신설에 따른 하위법령 마련 나. 도로점용료에 대한 경과규정 명확화(안 부칙 제6조) ㅇ 영 제27751호 도로법 시행령 일부개정령안 부칙 제6조에서 규정한 도로점용료에 대한 경과규정을 명확하게 하여 행정업무상 혼란 예방 3. 의견제출 이 개정안에 대해 의견이 있는 기관․단체 또는 개인은 2017년 3월 20일까지 통합입법예고센터 (http://opinion.lawmaking.go.kr)를 통하여 온라인으로 의견을 제출하시거나, 다음 사항을 기재한 의견서를 국토교통부장관에게 제출하여 주시기 바랍니다. 가. 예고 사항에 대한 찬성 또는 반대 의견(반대 시 이유 명시) 나. 성명(기관ㆍ단체의 경우 기관ㆍ단체명과 대표자명), 주소 및 전화번호다. 그 밖의 참고 사항 등※ 제출의견 보내실 곳 - 일반우편 : (30103) 세종특별자치시 도움6로 11 국토교통부 도로운영과- 전자우편 : jwsuh@korea.kr- 전화 : 044-201-3920 / 팩스 : 044-201-5591',
'id': '국토교통부공고제2017-411호20170316',
'datetime': '2017-03-16T00:00:00+00:00',
'signature': '국토교통부장관',
'department': '국토교통부',
'title': '국토교통부공고제2017-411호',
'summary': ['도로법 시행령 을 개정하는 데에 있어, 그 개정이유와 주요내용을 국민에게 미리 알려 이에 대한',
'의견을 듣기 위하여 행정절차법 제41조에 따라 다음과 같이 공고합니다.']}
이 데이터는 다음과 같은 key가 존재합니다.
- cotents : 관보의 본문입니다.
- id : 관보의 이름입니다.
- datatime : 발행 일자입니다.
- signature : 책임자입니다.
- department : 정부부처입니다.
- title : 관보의 이름입니다.
- summary : 관보 내용의 요약입니다.
1
docs[1].keys()
dict_keys(['content', 'id', 'datetime', 'signature', 'department', 'title', 'summary'])
저희가 필요한 것은 contents 파트이니, 필요한 친구만 사용하기 편하게 List형태로 만들어 줍시다. 변수명은 코드의 프로세스 별로 docs+stepNumber 이렇게 붙여보겠습니다.
1
2
3
4
docs2 = []
for i in docs:
docs2.append(i['content'])
docs2[1]
' 도로법 시행령 을 개정하는 데에 있어, 그 개정이유와 주요내용을 국민에게 미리 알려 이에 대한 의견을 듣기 위하여 행정절차법 제41조에 따라 다음과 같이 공고합니다.
2017년 3월 16일 국토교통부장관 도로법 시행령 일부개정령(안) 입법예고 1. 개정이유 도로법 제68조 도로점용료 감면조항에「영유아보육법」제2조제3호에 따른 어린이집
또는「유아교 육법」제2조제2호에 따른 유치원(민간어린이집과 민간유치원)에 출입하기 위하여 통행로로 사용하는경우가 신설되었기에 이에 대한 하위법령을 마련하고자 함2.
주요내용 가. 도로점용료 감면 대상 추가(안 제73조제3항제1호가목) ㅇ 도로법 제68조(점용료 징수의 제한) 제9호 “「영유아보육법」제2조제3호에 따른 어린이집 또는
「유아교육법」제2조제2호에 따른 유치원에 출입하기 위하여 통행로로 사용하는 경우” 신설에 따른 하위법령 마련 나. 도로점용료에 대한 경과규정 명확화(안 부칙 제6조)
ㅇ 영 제27751호 도로법 시행령 일부개정령안 부칙 제6조에서 규정한 도로점용료에 대한 경과규정을 명확하게 하여 행정업무상 혼란 예방 3. 의견제출 이 개정안에
대해 의견이 있는 기관․단체 또는 개인은 2017년 3월 20일까지 통합입법예고센터 (http://opinion.lawmaking.go.kr)를 통하여 온라인으로 의견을 제출하시거나,
다음 사항을 기재한 의견서를 국토교통부장관에게 제출하여 주시기 바랍니다. 가. 예고 사항에 대한 찬성 또는 반대 의견(반대 시 이유 명시) 나. 성명(기관ㆍ단체의 경우
기관ㆍ단체명과 대표자명), 주소 및 전화번호다. 그 밖의 참고 사항 등※ 제출의견 보내실 곳 - 일반우편 : (30103) 세종특별자치시 도움6로 11 국토교통부 도로운영과-
전자우편 : jwsuh@korea.kr- 전화 : 044-201-3920 / 팩스 : 044-201-5591'
tokenize 전처리
전처리 과정은 다음과 같이 진행됩니다. 여기서 tokenize는 형태소 단위의 단어로 쪼개어 단어의 백터를 만들어 낼 기초 재료를 만든다는 의미입니다. 하지만 분석의 편의를 위해 형태소 단위가 아닌 단어의 단위에서 분석을 해볼려고 합니다. 이번시간에는 가장 기초적으로 문장을 띄어쓰기 단위로 쪼개고 그 다음에 불용어를 제거해 봅시다.
우선 대표 데이터 docs[1]을 바탕으로 분석을 진행해 보겠습니다.
- 정규표현식을 이용한 숫자 및 특수문자 제거 -> docs3
- Pos 태깅 -> docs4
- 불용어 제거 -> docs5
- bigram -> docs6
정규표현식
정규 표현식에서 한글을 인식하는 코드는 다음과 같습니다.
- hangul = re.compile(‘[^ ㄱ-ㅎㅣ가-힣]+’)
이를 바탕으로 한글 외 다른 의미를 구성하는 단어들을 제거해 줍시다
1
2
3
4
5
6
7
docs3 = []
for i in docs2:
hangul = re.compile('[^ ㄱ-ㅎㅣ가-힣]+')
result = hangul.sub('',i)
final = result.strip()
docs3.append(final)
docs3[1]
'도로법 시행령 을 개정하는 데에 있어 그 개정이유와 주요내용을 국민에게 미리 알려 이에 대한 의견을 듣기 위하여 행정절차법 제조에 따라 다음과 같이 공고합니다 년
월 일 국토교통부장관 도로법 시행령 일부개정령안 입법예고 개정이유 도로법 제조 도로점용료 감면조항에영유아보육법제조제호에 따른 어린이집 또는유아교 육법제조제호에
따른 유치원민간어린이집과 민간유치원에 출입하기 위하여 통행로로 사용하는경우가 신설되었기에 이에 대한 하위법령을 마련하고자 함 주요내용 가 도로점용료 감면 대상
추가안 제조제항제호가목 ㅇ 도로법 제조점용료 징수의 제한 제호 영유아보육법제조제호에 따른 어린이집 또는유아교육법제조제호에 따른 유치원에 출입하기 위하여 통행로로
사용하는 경우 신설에 따른 하위법령 마련 나 도로점용료에 대한 경과규정 명확화안 부칙 제조 ㅇ 영 제호 도로법 시행령 일부개정령안 부칙 제조에서 규정한 도로점용료에
대한 경과규정을 명확하게 하여 행정업무상 혼란 예방 의견제출 이 개정안에 대해 의견이 있는 기관단체 또는 개인은 년 월 일까지 통합입법예고센터 를 통하여 온라인으로
의견을 제출하시거나 다음 사항을 기재한 의견서를 국토교통부장관에게 제출하여 주시기 바랍니다 가 예고 사항에 대한 찬성 또는 반대 의견반대 시 이유 명시 나 성명기관단체의
경우 기관단체명과 대표자명 주소 및 전화번호다 그 밖의 참고 사항 등 제출의견 보내실 곳 일반우편 세종특별자치시 도움로 국토교통부 도로운영과 전자우편 전화
팩스'
관보 문서에 대한 불용어 처리
관보 문서에서 topicmodeling을 진행함에 있어서의 목적은 본 문서를 대표할수 있는 주제어 태그를 붙이는 것이였습니다. 즉 내용이 더 프로젝트에 더 영향력이 더 컷기 때문에 지역이나, 일반적인 관보에서 사용되는 용어에 대하여 불용어 처리를 진행하였습니다.
1
2
3
4
5
6
stopdoc = db.stopword.find()
stopdocs = list(stopdoc)
stoplist = []
for i in stopdocs:
stoplist.append(i['keyword'])
stoplist[0:10]
['중앙동7가', '대흥동', '양학리', '상반천리', '삼천1동', '율도리', '동매리', '거모동', '남원읍', '용주리']
POS 태깅
영어 문서의 경우는 띄어쓰기를 기반으로 형태소를 나눌 수 있었습니다. 하지만 한글의 경우에는 문장 내에서 의미를 나타내는 품사는 한정적입니다. 주로 명사, 형용사, 동사가 주된 역할을 하게 되죠. 이 떄문에 문장성분에 대한 이해가 필요합니다. 문장성분이란 한 문장을 구성하는 요소들을 문법적 기능에 따라 나눈 것을 가리킵니다. 여기서 문법적 기능이란 그 요소가 해당 문장 속에서 다른 요소와 어떤 (문법적) 관계를 가지면서 어떤 일을 하고 있는가를 나타냅니다. 예컨대 ‘주어’는 서술어가 나타내는 동작이나 상태의 주체가 되는 말입니다. ‘목적어’는 타동사가 쓰인 문장에서 동작의 대상이 되는 말입니다. ‘서술어’는 한 문장에서 주어의 움직임, 상태, 성질 따위를 서술하는 말입니다. 문장성분을 분석한다는 말은 문장이 주어졌을 때 주어, 목적어, 서술어 등으로 나누어 생각해본다는 뜻입니다. 문장성분을 확인할 땐 형태론적, 통사론적, 의미론적 기준이 있습니다.
때문에 문장에서 주된 의미를 구성하는, 명사는 주로 주어와 목적어와 같은 행위나 동작의 대상, 그리고 형용사와 동사는 서술어와 같은 상태나 성질을 대변하게 됩니다. 이를 위해 저희는 각 품사에 대한 정보를 알면 좋습니다.
현재 코어닷 투데이는 API의 형태로 형태소 분석기를 제공하고 있습니다. 그 활용 방법을 보시죠 튜토리얼 문서는 __여기__서 확인!
1
2
3
4
5
6
7
8
9
10
11
tclient = nlp.TextClient(api_host='unist.core.today')
tdb = tclient.lda
docs4 = []
def preprocessing(data, stopword):
tdb.bin.bucket = data
tdb.bin.tagging()
big1 = tdb.bin.tag_to_list(pos=['NNP','NNG','VA'], limit=['term'])
big1 = [word for word in big1 if word not in stopword]
# 단어 길이가 1이면 제거한다.
big2 = [token for token in big1 if len(token) > 1]
docs4.append(big2)
이제 위에서 영어와 특수용어를 제거한 200개의 국토교통부 관보 데이터 docs3에 위 전처리 함수를 넣어줍시다.
1
2
3
for i in docs3:
preprocessing(i, stoplist)
docs4[1]
['도로법', '을', '이유', '주요', '국민', '행정절차법', '제조', '국토교통부장관', '도로법', '부개', '정령', '입법예고', '이유', '도로법', '제조', '도로', '점용료','감면', '조항', '영유아보육법 '제조', '어린이집', '유아', '팩스'...]
Bigram과 Trigram을 만들어봅니다
bigram과 trigram은 동시등장성을 기반으로 연관있는 단어를 특정한 window size를 기반으로 묶어줍니다. 띄어쓰기 단위로 분리를 했을때 효과적으로 단어를 인식하게 도와줍니다.
- 연어는 보통 단어의 행위와 주체를 연결해주기 좋기때문에 관대한 parameter를 적용합니다
- Trigram은 보통 크게 관련이 없기 때문에 엄격한 파라미터를 적용합니다.
1
2
3
4
5
6
7
8
9
10
11
12
from gensim.models import Phrases
# 모델을 만들어 주고 trashhold를 지정해 줍시다.
bigram = Phrases(docs4, min_count=2, threshold=50)
bigram_mod = gensim.models.phrases.Phraser(bigram)
docs5 = []
for i in docs4:
a = bigram_mod[i]
docs5.append(a)
docs5[1]
docs5 = []
for i in docs4:
a = bigram_mod[i]
docs5.append(a)
1
docs5 = []
2
for i in docs4:
3
a = bigram_mod[i]
4
docs5.append(a)
docs5[1]
1
docs5[1]
['도로법',
'을 ',
'이유_주요',
'국민_행정절차법',
'제조',
'국토교통부장관',
'도로법',
'부개_정령',
'입법예고_이유',
'도로법',
'제조',
'도로',
'점용료_감면',
'조항',
'영유아보육법',
'제조',
'어린이집',
'유아',
'육법',
'제조',
'유치원',
'민간',
'어린이집',
'민간',...]
보는것과 같이 이제 기본적인 token들의 연어처리가 완료됩니다.
Bag of words
이제 위 데이터를 어떻게 표현해야할까요? 이제 단어를 documents의 관점에서 표현하는 방식이 있습니다. 각 단어가 독립임을 가정하고, 문서를 표현하는 방식이 bag of words 입니다. 단어 하나에 인덱스 정수를 할당하는 방식입니다. 그렇다면 말뭉치 corpus에 있는 단어의 갯수와 같은 크기의 백터가 만들어지고, 단어마다 인덱스가 생성됩니다. 단어가 각 문서에 나온 횟수만큼 해당 단어 백터의 count를 늘려 나갑니다. 단어의 등장 순서를 무시하고, 문서 내 빈도를 따져서 문서를 표현합니다. 기본적으로 문서를 구성하는 단어를 독립적임을 생각하셔야 합니다.
문서를 벡터로 변화시킬때, 우리는 Bag_of_words라는 방식을 사용합니다. 각각의 단어는 vector의 요소 i애 대표되게 됩니다.
vector_i = doc 안에서 i번째 단어가 등장한 횟수
Documents-Term matrix(DTM) = Bag of words를 문서 집합에서 표현하게 된다면
Doc이라는 record에 term이라는 feature를 가진 matrix를 가질수 있다.
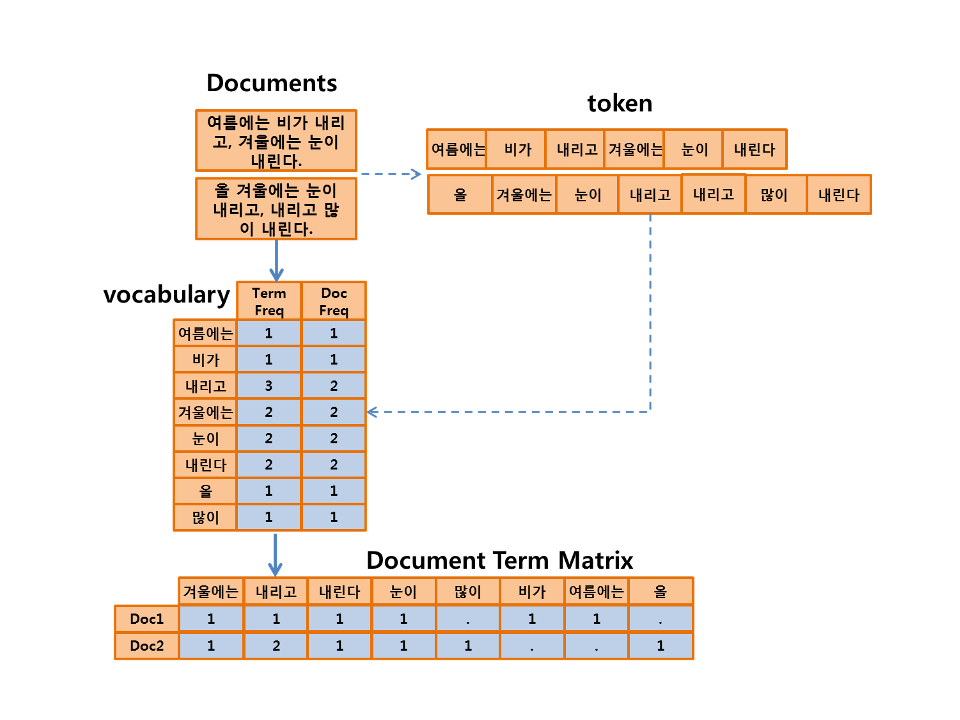
gensim에서 bow를 구현하는 방법 : Dictionary
이 모듈은 기본적으로 단어(token)을 숫자 integer id로 맵핑하는 함수 입니다.
gensim.corpora.dictionary.Dictionary(documents=None, prune_at=2000000)
- documents(iterable 가능한 str 값) : tokens들로 쪼개진 iterable한 문서의 집합입니다.
- prune_at : 최대 단어의 갯수를 제한할 수 있습니다, 너무 많은 양의 tokens 이 들어가는걸 방지하기 위함입니다.
Dictionarty function
- token2id : dict 객체를 반환 (token -> tokenid)
- id2token : dict 객체를 반환 (tokenid -> token)
- dfs - dict 객체를 반환 (문서내 frequency:token id),문서가 얼마나 많은 토큰을 보유하는가?
- num_docs : input으로 들어온 doc의 갯수
- num_pos : corpus의 총 갯수 (처리된 토큰 개수)
- num_nnz : BOW matrix에서 0이 아닌 값들의 합, 전체
1
2
3
4
5
from gensim import corpora
from gensim.corpora import Dictionary
# 일단 dictionary 형태로 만들어볼까?
dictionary = Dictionary(docs5)
1
2
# 빈도와 token id 를 보여줍니다.
dictionary.dfs
{39: 1,
27: 6,
88: 83,
123: 60,
42: 136,
18: 101,
196: 8,
26: 13,
25: 30,
181: 197,
33: 22,...}
1
dictionary.num_docs, dictionary.num_pos, dictionary.num_nnz
(200, 137905, 30740)
1
2
# token과 id의 관계를 보여줍니다.
dictionary.token2id
{'가각_전제': 0,
'가감_차선': 1,
'가능': 2,
'가스': 3,
'가스_공급': 4,
'가스공급설비': 5,
'갈매': 6,
'갈음': 7,
'개소': 8,
'건축물': 9,
'게재_생략': 10,
'결정': 11,
'경관': 12,
'계획': 13,
'고개': 14,
'고등학교': 15,
'고려': 16,
'고속도': 17,
'고시': 18,
'공간': 19,
'공공': 20,
'공공_분양': 21,
'공공공지': 22,...}
1
print(dictionary)
Dictionary(11297 unique tokens: ['가각_전제', '가감_차선', '가능', '가스', '가스_공급']...)
11297개의 token이라니 너무 많은것 같지 않나요?? 뭔가 관보 문서에 일반적인 데이터도 많을 것으로 예상됩니다. 이를 필터링에 대한 필요성이 있습니다.
filter_extremes : 이렇게 만들어진 사전의 토큰 중, 일부를 필터링 하고 싶다면
Dictionary객체에 filter_extremes과 remove_n을 통해 outlier를 제거할 수 있습니다. frequency를 기반으로 적은
filter_extremes(no_below=5, no_above=0.5, keep_n=100000, keep_tokens=None)
- no_below : 정수를 인자로 받으면서, 적어도 이 숫자 이상있는 단어들을 보존 합니다
- no_above : 유리수를 인자로 받으면서, 전체 문서 중 몇 일정 비율 이상 속해있지 않는 단어들을 보존합니다.
- keep_n : 빈도가 높은 token들로 sorting을 진행한 후, 빈도가 높은 순으로 짜릅니다. 1,2번 이후 진행됩니다.
filter_n_most_frequent(remove_n)
- remove_n (int) – 가장 높은 빈도의 단어를, 해당 숫자만큼 제거합니다.
filter_tokens(bad_ids=None, good_ids=None)
- 해당 token의 ids를 안다면 다음과 같은 방식으로도 필터를 할 수 있습니다.
1
2
dictionary.filter_extremes(no_above=0.5)
print(dictionary)
Dictionary(1269 unique tokens: ['가각_전제', '가능', '가스', '가스_공급', '갈음']...)
token의 갯수가 줄었으며, 문서의 대표성을 표현하는 단어들이 더 많이 남았을 것으로 예상됩니다.
Add_documents : 만약에 새로운 데이터가 들어오면 어떻게 처리해야할까요?
새로운 문장을 전처리하는 방법
add_documents(documents, prune_at=2000000)
1
2
3
4
5
6
7
add_doc = ['교육훈련기관 변경사항 「철도안전법」제16조 및 같은 법 시행령 제18조제2항에 따라 철도차량 운전면허 교육훈련기관의 변경사항에 대하여 다음과 같이
고시합니다. 2018년 2월 27일 국토교통부장관 [교육훈련기관 변경사항] 변경사항 지정일자 기관명 사업장 소재지 변경항목 당초 변경 한국교통 충청북도 충주시 대
2011.1.24. 대표자 김영호 이병찬 대학교 소원면 대학로 50', '민간임대주택에 관한 특별법 시행규칙 일부개정령을 다음과 같이 공포한다. 2018년 3월 29일
국토교통부장관 민간임대주택에 관한 특별법 시행규칙 일부개정령 민간임대주택에 관한 특별법 시행규칙 일부를 다음과 같이 개정한다. 제2조제3항 및 제4항 중 “영
제4조제4항”을 각각 “영 제4조제5항”으로 한다. 제3조제1항 및 제4항 중 “영 제4조제6항”을 각각 “영 제4조제7항”으로 한다. 별지 제24호서식 및 별지 제25호
서식을 각각 별지와 같이 한다. 부 칙 이 규칙은 공포한 날부터 시행한다. ◇개정이유 및 주요내용 민간임대주택의 표준임대차계약서에 해당 주택이 임대의무기간 내
양도 및 임대료 증액 범위 등의 제한을 받는 민간임대주택에 해당함을 명시하여 민간임대주택 임차인의 권리 보호를 강화하 려는 것임.']
만약 다음과 같은 문서가 새로 수집되었다고 가정해 봅시다. 하지만 위 문서들은 전처리가 되어있지 않습니다. 최대한 비슷하게 만들어 주는것이 중요합니다! 전에 전처리 함수를 만들어 뒀다는걸 기억하세요!
preprocessing 함수에서 객체명을 docs4로 작성했으니 다시한번 빈 list로 선언을 해줍시다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
add_doc2 = []
for i in add_doc:
hangul = re.compile('[^ ㄱ-ㅎㅣ가-힣]+')
result = hangul.sub('',i)
final = result.strip()
add_doc2.append(final)
docs4 = []
for i in add_doc2:
preprocessing(i, stoplist)
add_doc3 = []
for i in docs4:
a = bigram_mod[i]
add_doc3.append(a)
add_doc3
[['교육훈련기관',
'변경',
'사항',
'철도안전법',
'제조',
'같은 법',
'제조',
'철도차량',
'운전_면허',
'교육훈련기관',
'변경',
'사항',
'고시',
'국토교통부장관',
'교육훈련기관',
'변경',
'사항',
'변경',
'사항',...]
이제 전처리가 완료된 token들이 len=2 짜리 list에 저장된 것을 볼 수 있습니다.
1
2
dictionary.add_documents(add_doc3)
print(dictionary)
202
Dictionary(1289 unique tokens: ['가각_전제', '가능', '가스', '가스_공급', '갈음']...)
data save
처리가 완료된 데이터를 파일 형태로 저장할 수 있습니다.
1
2
dictionary.save('stop&bi(min=2,threshold=50,no_above=0.5).dict')
corpora.MmCorpus.serialize('stop&bi(min=2,threshold=50,no_above=0.5).mm', corpus)