LDA 파라미터를 튜닝해보자!
본 문서는 Topic modelling을 진행하면서, 좋은 LDA모델이 만들어 졌는가에 대한 평가기준을 만들기 위해서, 주제 일관성 이라는 개념을 가지고 저희가 설계한 모델을 평가하는 방법에 대해서 알아보려고 합니다.
사용한 라이브러
1
2
3
4
5
6
7
8
9
10
11
12
from pymongo import MongoClient
import pandas as pd
import numpy as np
import re
import coredottext.nlp as nlp
import json
import warnings
import pyLDAvis.gensim
from gensim.models.coherencemodel import CoherenceModel
from gensim.models.ldamodel import LdaModel
from gensim.corpora.dictionary import Dictionary
import time
데이터 로드
지난 시간에 만들었던 corpus 와 dictionary 객체를 호출합니다. 이미 전처리가 끝난 객체들은 LDA의 모형에 input으로 들어오게 됩니다.
1
2
3
4
5
6
7
8
from gensim import corpora, models, similarities
import os
if (os.path.exists('stop&bi(min=2,threshold=50,no_above=0.5).dict')):
dictionary = corpora.Dictionary.load('stop&bi(min=2,threshold=50,no_above=0.5).dict')
corpus = corpora.MmCorpus('stop&bi(min=2,threshold=50,no_above=0.5).mm')
print("Dictionary와 corpus가 준비되었습니다!")
else:
print("데이터가 없어요!")
이제 한번 각각 토큰들과 도큐먼트 숫자를 확인해봅시다
1
2
print("unique token: %d" % len(dictionary))
print("number of documents: %d" % len(corpus))
모델 학습 시작
우리는 이제 LDA model를 학습시켜봅시다. 모형 자체에 대한 설명은 잠시 미루어두고, 우선 학습 파라미터를 먼저 봅시다.
- topic : 당신이 가설로 잡은 토픽의 갯수는?
- chunksize : 얼마나 많은 문서가 훈련 알고리즘에 사용되는가?
- 만약에 빠른 학습이 중요하시다면, 청크사이즈를 키워서 돌려봅시다!
- Hoffman의 논문에 의하면 Chunksize는 모델 품질에 영향을 미치지만 차이그 그렇게 크진 않다고 합니다!
- passes : 패스는 모델 학습시 전체 코퍼스에서 모델을 학습시키는 빈도를 제어한다고 합니다.
- epochs 와 같은 용어 같다!
- model를 학습시키는 횟수를 말하는것 같아요! model sampling?
- iteration : 각각 문서에 대해서 루프를 얼마나 돌리는지를 제어한다고 합니다.
- pass & iteration 은 최대한 많은게 좋다!
- eval_every = 1 in LdaModel
- alpha, eta = auto, 디리클레 분포의 감마함수에 대한 파라미터입니다!
저희는 오늘 이 파라미터중 topic 의 갯수, 그리고 passes 를 변화시켜보면서 더 좋은 모델을 설계해 보려고 합니다.
Measure? 평가기준은 어떻게 잡아야하나요?
바로 Perplexity, Topic Coherence입니다.
-
Perplexity
perpelxity는 사전적으로는 혼란도 라고 쓰인다고 합니다. 즉 특정 확률 모델이 실제도 관측되는 값을 어마나 잘 예측하는지를 뜻합니다. Perlexity값이 작으면 토픽모델이 문서를 잘 반영된다고 알 수 있습니다. 따라서 작아지는것이 중요합니다.- 의미 의미확률 모델이 결과를 얼마나 정확하게 예측하는지.낮을수록 정확하게 예측.
- 토픽 모델링 기법이 얼마나 빠르게 수렴하는지 확인할 때,
- 확률 모델이 다른 모델에 비해 얼마나 개선되었는지 평가할 때,
- 동일 모델 내 파라미터에 따른 성능 평가할 때 주로 사용
- 한계 Perplexity가 낮다고 해서, 결과가 해석 용이하다는 의미가 아님
-
Coherence
이와달리 coherence는 주제의 일관성을 측정합니다. 해당 토픽모델이, 모델링이 잘 되었을수록 한 주제 안에는 의미론적으로 유사한 단어가 많이 모여있게 마련입니다. 따라서 상위 단어 간의 유사도를 계산하면 실제로 해당 주제가 의미론적으로 일치하는 단어들끼리 모여있는지 알 수 있습니다.- 토픽이 얼마나 의미론적으로 일관성 있는지.
- 높을수록 의미론적 일관성 높음
- 해당 모델이 얼마나 실제로 의미있는 결과를 내는지 확인하기 위해 사용
- 평가를 진행하기 위해 다른 외부 데이터(코퍼스, 시소러스 등)가 필요
주의사항!
어떻게 문서들 집합간의 일관성을 정량화 할 것인가? 문서 집합의 Coherence 가 높아지면 monotonic 해지는 문제점이 생긴다. 하지만 다른 사실을 추가한다면 단조로움이 보다 감소되는 경향이 있다. 이 것은 마치 Bias-Variance tradeoff 처럼, 만약 특정 coherence가 너무 높아지면 정보의 양이 줄어들게 되고, coherence가 너무 낮아 정보들이 인관성이 없다면, 분석의 의미가 낲아지게 됩니다.
이제 시작해봅시다!
기본적인 INITALIZATION
1
2
3
4
5
6
7
8
9
10
11
12
# 파라미터를 튜닝해볼까!
num_topics = 10
chunksize = 2000
passes = 20
iterations = 400
eval_every = None
%time model = LdaModel(corpus = corpus, id2word = id2word, chunksize = chunksize,\
alpha ="auto", eta="auto",\
iterations = iterations, num_topics = num_topics,\
passes = passes, eval_every = eval_every)
이후에 gensim에서는 CoherenceModel이라는 class와 LdaModel 내의 log_perplexity라는 함수를 통해서 구할수가 있습니다.
1
2
3
4
cm = CoherenceModel(model=model, corpus=corpus, coherence='u_mass')
coherence = cm.get_coherence()
print("Cpherence",coherence)
print('\nPerplexity: ', model.log_perplexity(corpus))
이렇게 돌려보면 다음과 같은 결과가 나옵니다.
Cpherence -1.6766831040643573
Perplexity: -5.233458042646217
이때 u_mass라는 새로운 파라미터가 보이는 군요 과연 이친구는 어떤 친구일까요??
U_mass Coherence
본 문서는 intrinsic measure로 알려져있는 U_mass coherence measure를 사용합니다. 위에서 w_i, w_j는 corpus안에 존재하는 단어를 뜻하게 됩니다. 그렇다면 D라는 함수는 무엇을 의미할까요?
D는 문서 내에서 특정 단어 $w_i$ 가 등장한 frequency를 뜻하게 됩니다. 는 두개의 단어가 동시에 하나의 문서에서 등장한 기반이 되는 것이죠. 상수항의 의미는 0이 되지 않게 하기위한 smoothing count의 역할을 하게 됩니다.
parameter tunning
이제 epoch 반복에 따른 coherence 의 변화를 살펴보려고합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
coherences=[]
perplexities=[]
passes=[]
warnings.filterwarnings('ignore')
for i in range(10):
ntopics, nwords = 200, 100
if i==0:
p=1
else:
p=i*5
tic = time.time()
lda4 = LdaModel(corpus, id2word=dictionary, num_topics=ntopics, iterations=400, passes=p)
print('epoch',p,time.time() - tic)
# tfidf, corpus 무슨 차이?
# lda = models.ldamodel.LdaModel(corpus, id2word=dictionary, num_topics=ntopics, iterations=200000)
cm = CoherenceModel(model=lda4, corpus=corpus, coherence='u_mass')
coherence = cm.get_coherence()
print("Cpherence",coherence)
coherences.append(coherence)
print('Perplexity: ', lda4.log_perplexity(corpus),'\n\n')
perplexities.append(lda4.log_perplexity(corpus))
epoch 1 1.8167250156402588
Cpherence -1.3454745913956003
Perplexity: -5.8650687793838925
epoch 5 3.5294880867004395
Cpherence -1.3564542447869843
Perplexity: -5.412724141458075
epoch 10 5.450774669647217
Cpherence -1.301133873055966
Perplexity: -5.296108312323815
epoch 15 7.528485059738159
Cpherence -1.362746738471485
Perplexity: -5.255073912058971
epoch 20 9.316975116729736
Cpherence -1.3539493855727167
Perplexity: -5.202922878930245
epoch 25 11.632537841796875
Cpherence -1.3182261549029237
Perplexity: -5.194990750233764
epoch 30 13.422101020812988
Cpherence -1.4141993104693307
Perplexity: -5.189478636113676
epoch 35 16.768910884857178
Cpherence -1.3256829757699393
Perplexity: -5.191839782725926
epoch 40 17.01100182533264
Cpherence -1.343570230216711
Perplexity: -5.20019584597306
epoch 45 18.696186065673828
Cpherence -1.3646219020785635
Perplexity: -5.182808537051267
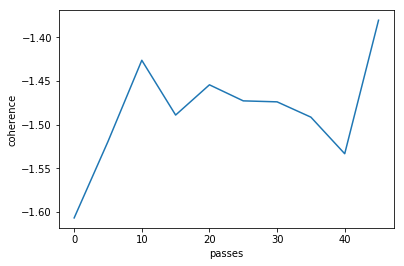
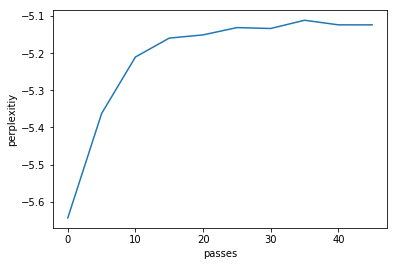
최적 topic의 갯수는?
네 제 생각에는 passes 가 30 일때 최적인것 같군요. 그런 이제 passes를 고정시킨뒤 최적 토픽 갯수를 구해봅시다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
coherencesT=[]
perplexitiesT=[]
passes=[]
warnings.filterwarnings('ignore')
for i in range(10):
if i==0:
ntopics = 2
else:
ntopics = 20*i
nwords = 100
tic = time.time()
lda4 = models.ldamodel.LdaModel(corpus, id2word=dictionary, num_topics=ntopics, iterations=400, passes=30)
print('ntopics',ntopics,time.time() - tic)
cm = CoherenceModel(model=lda4, corpus=corpus, coherence='u_mass')
coherence = cm.get_coherence()
print("Cpherence",coherence)
coherencesT.append(coherence)
print('Perplexity: ', lda4.log_perplexity(corpus),'\n\n')
perplexitiesT.append(lda4.log_perplexity(corpus))
결과는!
ntopics 2 6.226176023483276
Cpherence -0.8694563735288781
Perplexity: -5.5187873299354075
ntopics 20 8.4303560256958
Cpherence -1.6319113732667556
Perplexity: -5.185149301646774
ntopics 40 14.605365991592407
Cpherence -1.6538059370799985
Perplexity: -5.102639487196856
ntopics 60 10.919494152069092
Cpherence -1.9182083938523433
Perplexity: -5.111362587948968
ntopics 80 32.71963810920715
Cpherence -1.7965530173031365
Perplexity: -5.128915590594402
ntopics 100 25.167271852493286
Cpherence -1.5143368357888167
Perplexity: -5.138928902745652
ntopics 120 12.818365812301636
Cpherence -1.4409719336558429
Perplexity: -5.134092682997634
ntopics 140 13.15405011177063
Cpherence -1.4796698737980372
Perplexity: -5.131832419302965
ntopics 160 12.51957893371582
Cpherence -1.3620897356961623
Perplexity: -5.174852515618865
ntopics 180 13.924007892608643
Cpherence -1.3149172648634038
Perplexity: -5.185487132006173
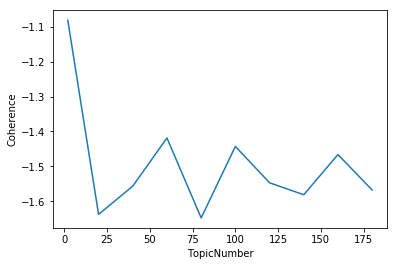
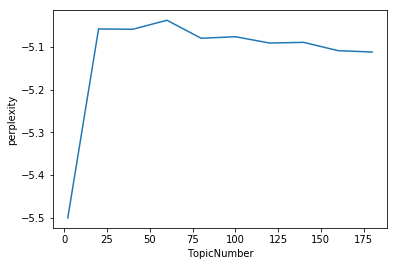
최적 토픽의 갯수는 30개인것으로 보입니다!